
タイトルが長いんだよなあ…。
愛のままにわがままに 僕は君だけを傷つけない!
統計キーワード集の続きです。


中身にはあえてあまり触れません。ご容赦ください。
①z検定
一番普通の主人公的検定方法
「正規分布」や「母集団の分散が既知」といった場合に使う。
要は普通の高校生ポジション。(なんだそれ)
普通すぎてz検定という言葉もあまり使われない。
分散が既知とは、例えば「前にも一回やってるからバラツキ具合は知ってるよ」みたいな話です。
またデータ数が多いときにも使えます。
データ数が多いということは前回の標準誤差SEを思い出して欲しいのですが、<標準偏差/√データ数>の分母が大きくなっていきますので、SEがどんどん小さくなっていきます。
データ少ない→ SE=10/√3 = 5.8 (標準誤差が大きい)
データ多い → SE=10/√5000 = 0.14(標準誤差が小さい)
このように標準誤差が小さくなっていく。イメージとして打席数が多いほど打率も実力値に近く収束していくのと同じ感覚です。
誤差(分散)が最初からわかっている時や誤差が小さいときはこのz検定です。
標準正規分布や1.96という数字が関わりが深いです。(ただし両側2.5%の場合)

【過去問H26】

前回調査と同じ(分散)予想と解釈出来ますので、これはz検定になります。
統計学ではお決まりの、推定範囲(0.03)=1.96×√(分散/n)の式を展開しただけですけど、ポイントは95%というキーワードから1.96を思い出すことです。
それでアかイの2択に絞れます。
あとは0.03×0.97か0.10×0.90のところですが、この部分は分散を示しています。
このように確率の話の場合、p×(1-p)で分散を算出できます。
だけどこの選択を一言で説明するのは難しい…。
大事なのはシェア10%であることか、誤差3%かどっちの数字だと思いますか?
誤差3%というのは例えば思いつきの数字みたいなもので、重要なのはシェア10%の方ですよね。
ですので0.10×0.90がこの(製品の分散を求める)式になんか正しそうだと判断出来れば最高です。答えはイ。
②t検定
主人公のライバル的検定。むちゃくちゃ使います。
だって普通は母集団の分散とか分からないですよね。
この池にいる鯉全部の体重の分散は?とか聞かれても知らんがなって話です。
それにこの池の鯉を5000匹捕まえて測定!とかもやってられないわけです。
まぁ10匹くらいは捕まえて測定してやってもいいですね。
こういう時はt検定になります。
データは数n=10ですので、SEはσ/√10となります。
最大の知っておくべきポイントは自由度が(n-1)になることです。
自由度って何?って話ですが、まぁ置いておきます。
とにかくこの場合の自由度は9(データ数10-1なので)です。
そして本来は自由度9のt検定の表を確認しにいく作業があるのですが、診断士試験には関係のないことです。
ともかく分散が未知、データ数も少ない検定ときたらt検定。
自由度ときたら基本的にデータ数n-1と知っておきましょう。
【過去問H23】

アはまず✕に出来ますね。自由度は9です。
イについては、平均値の区間推定ですからテストの偏差値を思い出してください。
平均点から95%の人が属する範囲を示せと言われて、-16点~16点とかっていわないですよね。平均点が仮に50点なら34点~66点というはずです。だから正確にはμ-1.96σ~μ+1.96σの範囲となります。(μは平均の意味)
ウは、今回データが少ないt検定なわけですから標準正規分布は使えません。というか平均値が0じゃないのでそもそも初期アバターは使えません。
エが消去法で選べます。z検定やt検定は基本正規分布を使います。
③ウェルチのt検定
t検定の難しい版です。強キャラ的検定です。
同じ1つの池の中で鯉を検定するなら分散は不明だとしても、必ず1つです。
でも別の2つの池から各々鯉を採取するなら話は変わってきます。
この場合、2種類の分散(正確な分散は不明なので厳密には不偏分散)を平均化してやる必要があります。
感覚としてはWACCと同じです。負債と自己資本の加重平均でコストを出すやり方。
ウェルチのt検定の式は↓こんな感じですけど

実際に出題されるときはこんなレベルです↓【過去問H20】

2つの池の標本的なやつはウェルチです。答えはア。
イは次に出てきますが無関係です。
ウも後で出てきますが無関係です。
エは母集団の標準偏差はわからないって言ってるのでz検定は無理です。
④χ2検定(カイニジョウ検定)
これも非常によく使います。ヒロイン的検定です。
先ほど池の鯉の体重を検定する場合t検定を使いました、その時分散なんか知らんがなといいました。
その知らんかった分散(母集団の分散)を推定するときに使います。
分散(σ2乗)を求めるのでなのでなんとなくカイ2乗と呼ぶのとイメージが一致するのではないでしょうか。
他に大きな特徴として「適合度」や「独立性」の検定なんかにも使います。
例えば調査した血液型の割合データが理論上の割合データと適合するかどうか、や
男と女のラーメンの好き嫌いに男女間で違いがあるかどうか(独立性)、などを調べるときです。
(それらも結局分散を利用して検定を行います)
なんせ表(クロス集計表)っぽいのが出てきたときもχ2検定です。
自由度は基本的にやはりn-1になりますが、表の場合の自由度はちょっと特殊です。
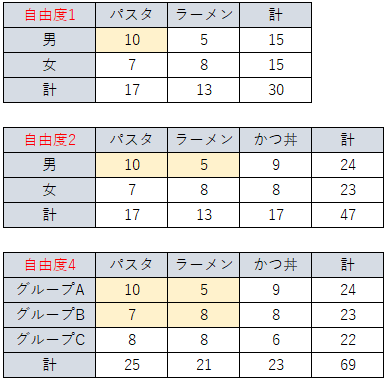
色枠の数が自由度の数です。
表が大きくなるほど自由度が増えます。
色枠の数え方は、計の行列と最後の行列を除いた箇所の個数です。
本来計の行列以外のすべてのデータマスが自由度の数になりそうですが、最後の行列はもしデータがなくても勝手に埋まりますよね?(計がわかっていれば)
だからデータマスの数にカウントしないんですね。
よくわかりませんが、そういうことだそうです。
【過去問H19】

表の自由度の法則を知っていれば一発です。答えはウ。
ちなみに仮に統計検定の試験だと想像すれば、χ2の付録表の自由度1と有意水準0.05の値を見にいって、3.84という値を確認。問題のクロス表から自分でχ2を7.53と計算して(面倒)、これらの数字を比較した上で、帰無仮説を棄却し、「関西と関東でA新聞とB新聞の普及度には差がある」と結論します。
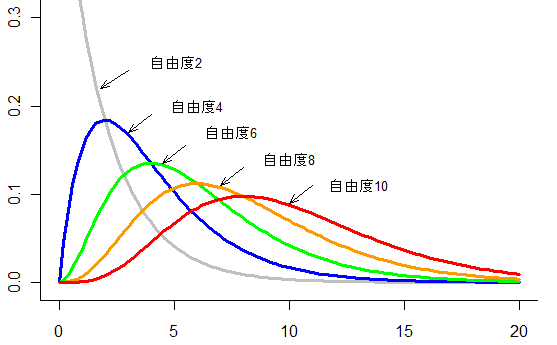
χ2分布の形は正規分布と大きく異なっており、こんな形です。
【過去問H26】

これは売上高の適合度を測るχ2検定になります。二乗和というキーワードからもなんとかχ2と導けるでしょうか…?
イは無理です。推定ではなくあくまで理論値との適合度を測るだけです。
ウは違います。上のグラフの通り、正規分布にはなりません。
エも違います。自由度が変わるとグラフの形は変わります。そのための自由度です。
消去法的にアになります。適合度検定は必然的に片側検定のみというルールがあります。
④F検定
ちょっと変わった先生的検定です
池の鯉を検定するとして、池鯉の分散がわかってるならz検定。
分散が不明ならt検定。2つの池ならウェルチ検定。
分散そのものを推定するならχ2検定。と見てきました。
じゃあ池が2個あるとして、その分散が一緒なのか違うのか、どれくらい分散が異なるのかもわからない場合はどうしたらいいでしょうか。
そういう時にF検定を行います。本番前の模試みたいなもんですね。
その後にt検定なりを行っていきます。
【過去問H25-第25問】

Aは、正規分布、十分な数のデータという情報からz検定。
Bは、少ないデータで分散が未知なのでt検定。
※2つの池があっても、その2つの池の分散が等しいといっているので、実質1つの池と考えても構いません。なのでウェルチではないです。
Cは、分散自体の調査、本番前の模試ですね。つまりF検定です。
⑤分散分析
ラスボス検定です。
池の鯉でいうと、分散不明の池が3つ以上出てきた場合ですね。
この場合に、分散分析を使います。
いやなんかのアルファベット検定っていう名前に統一しろよと思います。
「鯉」だけなので一元配置の分散分析といいます。
もし「鯉」だけでなく「鮒」もみる場合は二元配置の分散分析といいます。
もし「鯉」「鮒」「メダカ」も見る場合は多元配置の分散分析といいます。
カオスすぎます。
3個の池で、5箇所の支店で、10人の身体測定が~と標本集団が3つ以上になった時点で分散分析。
池の鯉だけなら、一元配置。
支店の売上と利益をみるなら、二元配置。
10人の体重と身長と腹囲と視力と聴力をみるなら、多元配置。
計算は人間のレベルを超えているので、大体PCで計算された数値表などがでてきますが、その辺は割愛。
【過去問H16 第18問】
当社には営業社員が3人いる。営業成績に違いが有るかどうかを調べるために、各社員について担当顧客の営業データをランダムに100件づつ抽出した。このデータの分析方法を選べ。
ア t検定
イ 判別分析
ウ 分散分析
エ 平均値の差の検定
営業(池にあたります)が3人いるのでウが正解です。
超表面的な問題です…。なんじゃこりゃ。
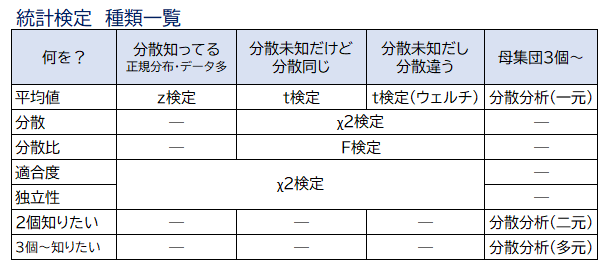
まとめ
続く